






标题:Kafka数据库实时流:构建高效数据处理的利器
引言
随着大数据时代的到来,实时数据处理成为企业提升竞争力的重要手段。Kafka作为一种分布式流处理平台,以其高吞吐量、可扩展性和容错性等特点,成为了构建实时数据处理的利器。本文将深入探讨Kafka数据库实时流的特点、应用场景以及如何实现高效的数据处理。
什么是Kafka数据库实时流
Kafka是由LinkedIn开发并捐赠给Apache软件基金会的开源流处理平台。它允许用户发布和订阅数据流,并存储这些数据流以供后续处理。Kafka数据库实时流的核心特点如下:
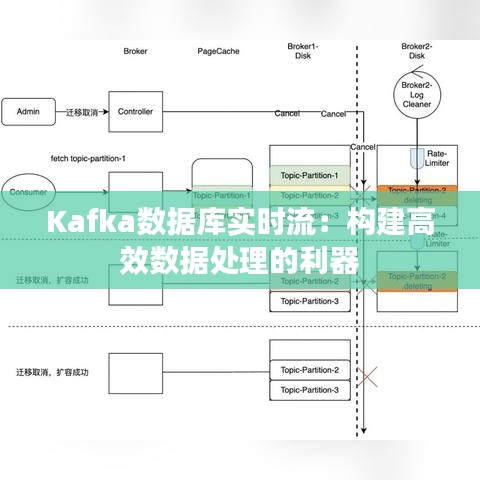
- 高吞吐量:Kafka能够处理每秒数百万条消息,适用于大规模数据流处理。
- 可扩展性:Kafka支持水平扩展,可以通过增加更多的节点来提高系统性能。
- 容错性:Kafka采用分布式存储,即使部分节点故障,系统仍能正常运行。
- 持久性:Kafka将数据存储在磁盘上,确保数据不会因为系统故障而丢失。
Kafka数据库实时流的应用场景
Kafka数据库实时流在各个领域都有广泛的应用,以下是一些典型的应用场景:
- 日志收集:Kafka可以收集来自各个系统的日志数据,便于后续分析和监控。
- 实时分析:Kafka可以实时处理和分析数据,为业务决策提供支持。
- 事件源:Kafka可以作为事件源,将业务事件实时传递给其他系统。
- 消息队列:Kafka可以作为消息队列,实现异步通信和数据交换。
如何实现Kafka数据库实时流
要实现Kafka数据库实时流,需要以下几个步骤:
- 搭建Kafka集群:首先需要搭建一个Kafka集群,包括多个Kafka节点。
- 创建主题:在Kafka中,数据被组织成主题(Topics),需要创建相应的主题来存储数据。
- 生产者发送数据:生产者负责将数据发送到Kafka主题中。
- 消费者消费数据:消费者从Kafka主题中读取数据,并进行处理。
- 数据处理:消费者可以对接各种数据处理工具,如Spark、Flink等,进行实时分析或存储。
案例分析:实时推荐系统
以下是一个使用Kafka数据库实时流构建实时推荐系统的案例:
- 用户行为数据通过生产者发送到Kafka主题。
- 消费者从Kafka主题中读取用户行为数据,并使用Spark进行实时分析。
- Spark分析结果通过消费者发送到推荐系统,实现实时推荐。
这种架构可以保证用户行为数据的实时性,提高推荐系统的准确性和响应速度。
总结
Kafka数据库实时流作为一种高效的数据处理平台,在各个领域都有广泛的应用。通过搭建Kafka集群、创建主题、生产者和消费者等步骤,可以实现实时数据处理,为业务决策提供有力支持。随着大数据时代的不断发展,Kafka数据库实时流将在更多场景中得到应用。
转载请注明来自四川春秋旅游有限责任公司锦绣路分社,本文标题:《Kafka数据库实时流:构建高效数据处理的利器》
百度分享代码,如果开启HTTPS请参考李洋个人博客





 蜀ICP备17014439号-1
蜀ICP备17014439号-1